



 Поделиться
Поделиться
Технологии успешного SOC: анализ данных
Предыдущие статьи данного цикла касались довольно прикладных для информационной безопасности тем, таких как источники данных, правила детектирования и сценарии реагирования. Однако, если обобщенно взглянуть на большинство процессов, связанных сегодня с Incident Response, да и в целом с Security Operations, то одним из основных узких мест является анализ большого объема данных, полученных из различных источников. А это означает, что с большой долей вероятности для решения прикладных задач информационной безопасности могут быть полезны те же инструменты, что используются для обработки данных в других сферах — все то, что сегодня называется термином Data Science. И столь популярные сейчас темы машинного и глубокого обучения как раз входят в раздел науки о данных (Data Science).
В силу высокого интереса современного рынка к темам ML/DL/AI, в совокупности с значительной сложностью в освоении и понимании используемых в этой сфере методов, многие производители, в том числе из сферы ИБ, часто спекулируют в своих рекламных проспектах данными понятиями и декларируют их как некую волшебную пулю от всех болезней информационной безопасности. Давайте же попробуем отсечь маркетинг и оценить существующий сегодня инструментарий анализа данных ИБ. Для этого воспользуемся опытом мирового кибер-сообщества, в котором помогут разобраться эксперты Security Vision: руководитель отдела развития продукта Данила Луцив и генеральный директор компании Руслан Рахметов.

Несомненно, современные вычислительные мощности, включая распределенное и облачное вычисления, а также новые инструменты работы с большими данными, которые уже зарекомендовали себя в различных сферах бизнеса, могут предоставить для решения задач информационной безопасности множество дешевых и эффективных решений. Анализ огромного объема данных как на предмет выявления известных паттернов и закономерностей, так и на выявление слабых сигналов и аномалий, сегодня не требует ни серьезных производственных мощностей, ни профессионального математического образования. С чего же в этом случае стоит начать?
Для рядовых сотрудников SOC дорога в Data Science выглядит достаточно тернистой, а перспективы получения применимых в работе результатов — смутные. Попробуем пройти этот путь, «стоя на плечах гигантов», и снова обратимся к статье Джона Ламберта (John Lambert) «Гитхабификация Информационной Безопасности» («The Githubification of InfoSec»), в которой он применяет термин Repeatable Analysis — «Воспроизводимый/Повторяемый анализ». На практике это означает, что мы с вами обладаем не только описанием проводимого другим специалистом аналитического исследования данных и его итоговыми результатами, но и можем воспроизвести все сделанные им шаги в режиме реального времени как на его данных, так и на своих собственных, не прикладывая к этому большого труда. И в качестве инструмента обмена подобного рода воспроизводимыми аналитическими исследованиями Джон, как и многие другие специалисты сегодня, отдает предпочтение технологии с открытым исходным кодом, реализованной в Jupyter Notebooks.
Jupyter — это набор технологий, созданных сообществом специалистов по исследованию данных. Основным концептом данной технологии является блокнот (Notebook). Он содержит в себе описательную часть в виде текста, формул и изображений, которые позволяют понять суть исследования, последовательности и применимость его этапов, способы интерпретации полученных данных, а также, собственно, сам программный код, производящий вычисления, каждый из блоков которого возвращает полученный на данном этапе результат.
Итеративность и наглядность процесса анализа делает Jupyter де-факто отраслевым стандартом для аналитиков данных. В конце 2020 г. исследователи JetBrains решили подсчитать количество блокнотов Jupyter на GitHub и обнаружили более 9,72 миллиона публично доступных файлов с восьмикратным увеличением их количества по сравнению с аналогичным исследованием трехлетней давности. Специалисты как в области теоретической науки, так и из вполне прикладных сфер, таких как предсказание поведения клиентов, анализ электоральных данных или флуктуаций излучения спутников, — все они с готовностью публично делятся результатами своих исследований.
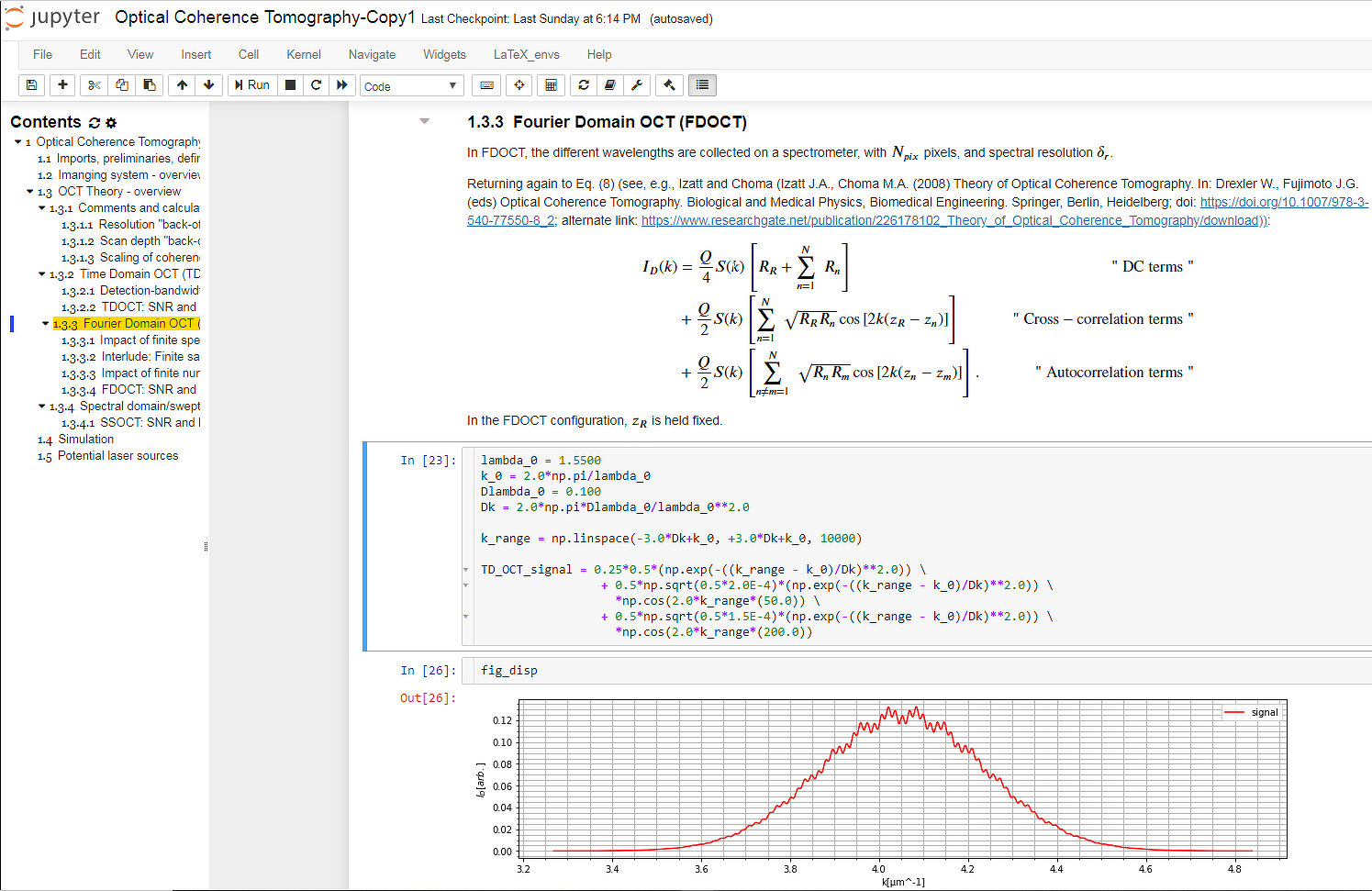
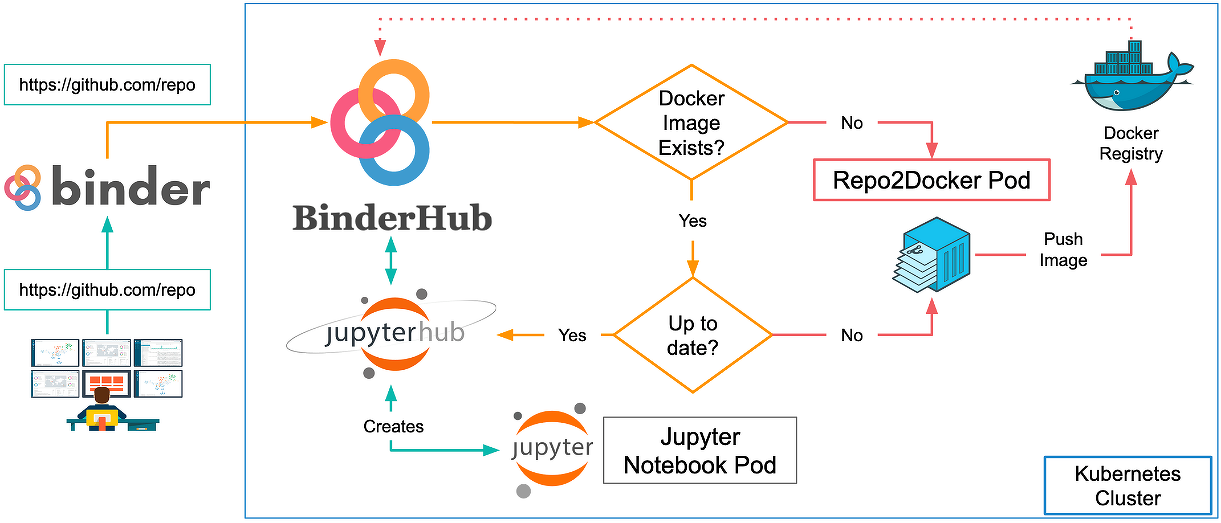
Для запуска вычислений в Jupyter требуется «ядро», то есть процесс, который будет запускать код на Python, .NET, R или других языках программирования и возвращать результат пользователю. «Ядро» может быть запущено на любой операционной системе прямо в браузере, вне зависимости от того, Windows это, Linux, Mac или мобильное устройство. «Ядро» может быть развернуто локально, удаленно или в облачной инфраструктуре. Как ни странно, последний пункт будет особенно интересен для начинающих исследователей данных. Такие сервисы, как mybinder, предоставляют доступ к «ядрам» со всеми необходимыми установленными библиотекам, так что пользователь за считанные минуты может воспроизвести исследование, имея под рукой только браузер. Большинство GitHub, содержавших Jupiter, сегодня прямо на основной странице имеют заветную кнопку Launch Binder. Один клик, несколько секунд — и полностью рабочий аналитический аппарат для воспроизведения исследования готов к работе.
Упомянутое выше исследование (кстати, тоже присутствующее в виде сырых данных и Jupyter блокнота) говорит следующее о деталях данной технологии:
- Несмотря на большой рост популярности R и Julia в последние годы, Python остается лидирующим программным языком для Jupyter-ноутбуков.
- 60% ноутбуков содержат в списке зависимостей Numpy, 47% импортируют Pandas. Это инструменты работы с сырыми данными в виде многомерных массивов — Numpy и гетерогенные табличные структуры или датафремов (dataframes) — Pandаs.
- В качестве инструментов графического представления наибольшую популярность сегодня имеют Matplotlib и набирающий популярность Seaborn, который делает все проще и красивее, чем у конкурента.
- Инструменты машинного обучения чаще всего представлены библиотеками Scikit-learn, torch и т.д., которые дают пользователю довольно широкий набор готовых алгоритмов SVMs, Random Forests, Logistic Regression и отлично подходят для новичков в ML и серьезными низкоуровневыми инструментами вроде TensorFlow, Keras, PyTorch.
Долгое время вся эта исследовательская активность обходила стороной сферу информационной безопасности, однако ситуация изменилась в 2019 г. после выхода цикла статей Роберто Родригеса (Roberto Rodriguez) «Threat Hunting with Jupyter Notebooks». В данной серии рассказывается о применимости библиотеки Pandas для анализа событий ИБ, так как она создана как раз для работы с разнородными табличными данными, такими, например, как логи SIEM-систем.
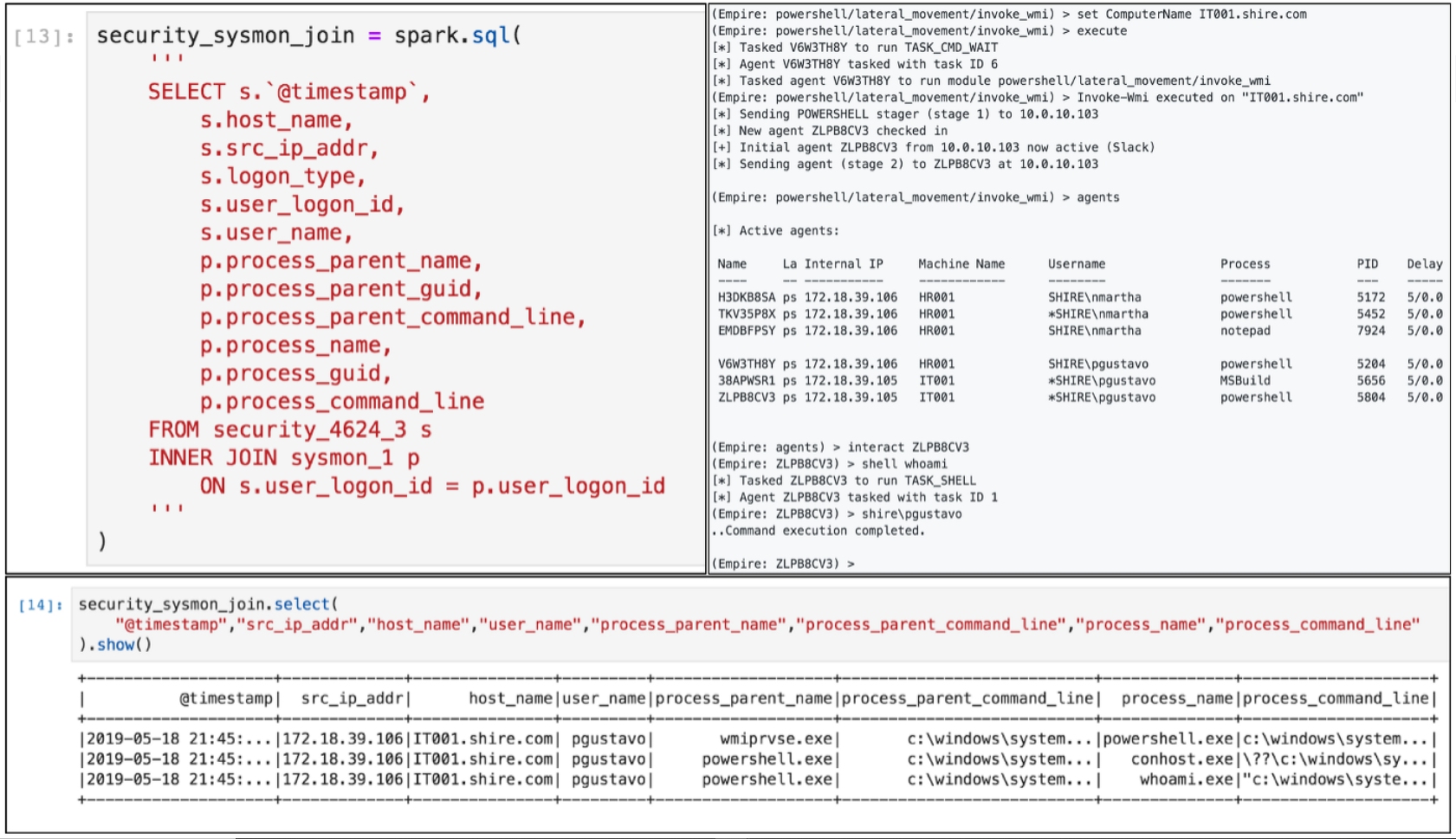
Уже в ознакомительной статье мы можем на примере расследования по логам системы, атакованной модулем lateral_movement/invoke_wmi из состава Powershell Empire, проследить за действиями исследователя.
 Интерактивное программирование в блокноте Jupyter. Простые последовательные однострочные запросы возвращают привычную для сотрудника SOC статистику по типам событий
Интерактивное программирование в блокноте Jupyter. Простые последовательные однострочные запросы возвращают привычную для сотрудника SOC статистику по типам событий
 Статистику по процессам
Статистику по процессам
 Позволяют тут же визуализировать всплески
Позволяют тут же визуализировать всплески
 Позволяют обнаружить изначальный источник инцидента
Позволяют обнаружить изначальный источник инцидента
Шаг за шагом мы можем проследить и воспроизвести каждый из его шагов, ознакомиться с приводимыми Роберто референсами, изменить запросы для более глубокого ознакомления с данными или попробовать воспроизвести их на собственных выборках событий, просто изменив источник.
Последующие статьи Родригеса рассказывают, как использовать Elasticsearch в качестве источника данных, а Apache Spark — в качестве SQL-like аналитического аппарата, что позволяет SOC-аналитику обзавестись столь необходимой функцией для расследования разрозненных событий, таких как JOIN, сцепляя на основании общего поля LogonID события аутентификации (Security EID 4624) и создания процесса (Sysmon EID 1).
Из этого цикла статей появились GitHub репозиторий и сайт Threat Hunter Playbook. На данный момент проект содержит более трех десятков расследований и множество полезных для исследователей справочных материалов. Все расследования ссылаются на упомянутую в предыдущих статьях библиотеку событий OTRF/Security-Datasets, также созданную братьями Родригесами.
![]()
Энтузиазм двух этих уроженцев Перу сложно переоценить, и для того, чтобы заразить им как можно больше людей, в 2020 г. ребята организовали онлайн-конференцию InfoSec Jupyterthon, где, помимо них, своими воспроизводимыми исследованиями делятся специалисты из Microsoft Threat Intelligence Center (MSTIC), Awake Security, Expel, Nvidia и ряда других компаний. InfoSec Jupyterthon формата 2021 г. развернулся уже в полную силу, заняв два полных дня, за время которых выступило два десятка спикеров и было проведено семь воркшопов. Итогом стало окончательное понимание того, что Data Science и информационная безопасность вместе надолго.
Так, Мехмет Эрген (Mehmet Ergene) рассказал о методе детектирования C2 Beaconing, то есть периодических подключений вредоносного ПО к серверам управления на основании статистического анализа событий сетевых подключений пользователей. Джо Потроске (Joe Potroske) из Target's Cyber Fusion Center продемонстрировал методы обнаружения обфусцированных Powershell на основании не статических правил корреляции, которые просто невозможно описать все, а на основании поиска самой обфускации через регрессионный анализ длинны PowerShell-команд и содержащихся в них символов. И, наконец, уже второй год подряд сотрудники Microsoft Threat Intelligence Center рассказывают о msticpy. Эта созданная сотрудниками центра исследования киберугроз компании Microsoft open source библиотека позволяет:
- получать данные о событиях безопасности из SIEM-систем и других источников;
- извлекать индикаторы активности (IoA) из логов и на лету распаковывать обфусцированные события;
- проводить анализ событий на выявление аномалий и декомпозицию временных рядов;
- обогащать данные, используя внешние источники, такие как VirusTotal, XForce, OTX, GreyNoise и другие;
- визуализировать результаты с помощью интерактивных временных шкал, деревьев процессов и графов.
 Примеры визуализаций событий в misticpy
Примеры визуализаций событий в misticpy
 Примеры визуализаций событий в misticpy
Примеры визуализаций событий в misticpy
На последнем форуме Positive Hack Days для нас было очень приятным открытием, что сотрудник компании Positive Technologies Антон Кутепов создал fork данной библиотеки, снабдив ее поддержкой MaxPartol SIEM в качестве источника событий.
Есть и ряд других свободно распространяемых проектов воспроизводимых исследований. Так, широко известный специалистам по информационной безопасности портал по анализу ресурсов в интернете DomainTools опубликовал свой Jupyter блокнот, иллюстрирующий взаимосвязи исследуемых доменов на основании общей инфраструктуры, информации о регистрации и паттернов имен.
Проект по визуализации взаимосвязей Threat Intel индукторов компрометации (IoCs), полученных в STIX-формате Stixview также обзавелся виджетом для среды интерактивных вычислений.

И это — только несколько примеров опубликованных исследований. Сегодня благодаря подобного рода технологиям обмена знаниями полностью стирается грань между фундаментальными исследователями в области Data Science, находящимися на авангарде защиты исследователями киберугроз международных SOC/CERT/CSIRT и всеми рядовыми специалистами ИБ по всему миру, только начинающими у себя в компании процесс построения Incident Response.
Наука о данных вошла во все сферы нашей жизни. ИТ-гиганты и финтех-стартапы, правительства государств и стриминговые сервисы — для всех них анализ больших данных и ML уже не есть какое-то «ноу-хау», а процесс, ежедневно находящий новые точки приложения и приносящий огромную прибыль, феноменально сокращая издержки на обработку данных. Задачи, стоящие перед сегодняшними SOC, методологически мало чем отличаются от задач в других сферах, и это означает, что сегодняшнему ИБ просто необходимо гораздо больше внимания уделить инструментам гибкой обработки данных, машиночитаемым форматам обмена экспертизой и взаимодействию всех членов кибер-сообщества для создания научного, воспроизводимого подхода к используемым нами методам и инструментам.
Рекламные проспекты решений по информационной безопасности и какой-то момент довольно сильно перегрели темы искусственного интеллекта (Artificial Intelligence) и машинного обучения (Machine Learning), сделав их фактически синонимом чего-то столь же сложного, малоприменимого и малополезного в реальной жизни. Открытые исследования на основе открытых же данных дают нам четкое понимание того, какие именно инструменты, методы и алгоритмы в каких ситуациях и при каких вредоносных активностях обеспечивают результаты выше, чем классические сигнатурные средства зашиты.
Вне зависимости от того, какие источники данных используют наши клиенты в платформе Security Vision: классические SIEM системы или инструменты работы с большими данными вроде Kafka,Spark, Hadoop, Zeppelin и т.д, продукт позволяет выстроить процесс получения, обогащения, анализа инцидента, а также выполнить действия по его обработке и устранению. Продукт может как самостоятельно оркестрировать имеющиеся у пользователя Jupyter блокноты, так и выступать источником информации и выполнять сценарии по внешнему запросу через Rest API интерфейс. Созданные нашими специалистами модели машинного обучения, интегрированные с платформой, позволяют значительно сократить нагрузку и затраты на использование SIEM-систем и детектировать аномалии, недоступные для выявления другими средствами анализа.
Поделиться
 Короткая ссылка
Короткая ссылка









