



 Поделиться
Поделиться
Технологии успешного SOC: детектирование атак и создание правил корреляции
Для того, чтобы создать основу успешного Detection Engineering, нужно сформировать приоритеты для источников событий информационной безопасности (ИБ), наладить их сбор, а также проанализировать, что именно могло бы содержать эти события в случае детектирования тех или иных тактик на примере датасетов симуляций атак. Так, хотя бы при post-mortem анализе, который напишется вне зависимости от исхода, будет достаточно информации для формирования цепочки событий. Можно сделать шаг дальше.
О проектах, которые должны стать настольным туториалом для технических специалистов, желающих наладить этапы построения процесса информационной безопасности, можно прочитать здесь и перейти на следующий этап. Проводниками будут руководитель отдела развития продукта Security Vision Данила Луцив и генеральный директор компании Руслан Рахметов. В цикле экспертных статей «Технологии успешного SOC» также есть о стратегиях и сценариях реагирования и анализе данных.
Однако назвать эффективным Security Operations Center (SOC), который не способен на ранних этапах детектировать вредоносную активность, язык не поворачивается. По этой причине следующим после обеспечения достаточности данных можно уверенно назвать этап формирования правил корреляции. Практически все компании, приобретавшие себе коммерческие SIEM-продукты, проходили все стадии жизненного цикла встроенного контента правил корреляции: «восторг», «отрицание», «гнев», «торг», «депрессия», «принятие», и, наконец, «отключение» встроенных правил и написание собственного контента.

Какие же концепты, существующие сегодня, дают специалистам SOC источники вдохновения на написание собственных правил детектирования? Мы уже говорили о том, что без Mitre ATT&CK сложно было бы представить всю существующую сегодня экосистему взаимосвязанных проектов в области практической информационной безопасности. И снова, важны не сами теги техник и тактик, а подход единого вендоро-независимого языка, описывающего технические принципы, которые лежат в основе как самих атак, так и методов их детектирования. Под общим языком мы понимаем те знания и структуры, которые можно выложить на GitHub или другой ресурс для совместной работы. Тут стоит вспомнить статью Антона Чувакина, которая для многих открыла термин Detection-as-Code. В статье говорится о необходимости внедрения подхода к написанию и тестированию правил детектирования, аналогичного тому, что используется в современной разработке программного кода.

Скептики могут сказать, что эйфория от Everything-as-Code проникла уже даже в консервативные головы безопасников. Однако сложно не увидеть явные плюсы такого подхода: версионность, обеспечение качества (Quality Assurance, QA) созданных правил детектирования, модулярность и повторное использование уже написанных блоков, кросс-вендорность и прочие преимущества внедрения автоматизированного цикла CI\CD — непрерывной интеграции или поставки (Continuous Integration or Continuous Delivery). Долгие годы во многих SIEM-системах создавать правила физически можно было только в графическом интерфейсе, без возможности копирования и редактирования блоков. По этой причине подобный подход вызывал разрыв шаблона и непонимание у многих участников отрасли, однако и существующие решения уже не могут соответствовать современным вызовам ландшафта киберугроз.
Созданные сообществом правила детектирования появились еще до ATT&CK фреймворка. Далеко не первым, однако одним из самых известных и до сих пор активно развивающихся проектов является Yara Rules. Его инструментарий представляет собой набор правил детектирования вредоносного программного обеспечения на основании совокупности строк и логических выражений, поиск которых производится в анализируемых файлах. Не удивительно, что этот язык появился в стенах широко известной компании VirusTotal. Yara-правила фактически стали стандартом для TI-обмена подобного рода информацией и широко используются в атрибуции, а также при Threat Hunting (циклическом поиске следов заражения или взлома, которые нельзя обнаружить стандартными средствами защиты).

Однако сфера форензики и анализа вредоносного ПО все же далека от массового профессионала ИБ. Большинство специалистов по кибербезопасности привыкли доверять антивирусам хотя бы при поиске в строчках бинарных файлов паттернов вредоносного ПО. По этой причине проект Yara, хоть и довольно хорошо известен, не претендует на звание всеобщего языка сотрудников SOC. Не менее полезными, однако столь же нишевыми можно назвать проекты, связанные с правилами детектирования сетевых атак на основе таких свободно распространяемых NIPS, как Snort и Suricata.
Безусловно вдохновляясь описанными выше инициативами, создатели проекта Sigma задумывали свою идею как «Yara для логов», и такой подход лег на крайне благодатную почву зародившегося ATT&CK Community. Если вкратце, то подобно другим Everything-as-Code-решениям, Sigma представляет собой данные, сериализованные в формате YAML. Такой подход позволяет как непосредственно импортировать данные правила в SIEM-системы (напрямую или через конверторы), так и работать с ними как с базой знаний. Все правила снабжены референсами на исследования специалистов по кибербезопасности, а также тэгами, которые позволяют понять, к каким именно техникам, тактикам и процедурам относятся данные детектируемые атаки. Часто Sigma-правила в своих тегах ссылаются на собственный Mitre-репозиторий правил детектирования, называемый Mitre CAR. Однако 541 существующая ATT&CK техника покрывается 3 781 правилом детектирования, 2 094 из которых реализованы в Sigma и еще примерно по 700 в Splunk и Elastic SIEM, а собственным CAR-идентификатором обладают лишь 178 техник.
Стоит отметить, что во встроенной поддержке на стороне SIEM-систем для интеграции Sigma-правил нет необходимости. Репозиторий Sigma содержит штатную утилиту Sigmac, которая позволяет конвертировать правила в запросы множества SIEM-систем, таких как Arcsight, Qradar, Splunk и многих других. Также ресурс Uncoder от компании SOC Prime позволяет не только конвертировать созданные сообществом правила, но и преобразовывать одни проприетарные правила в другие, что будет крайне полезно, например, при смене SIEM-вендора.
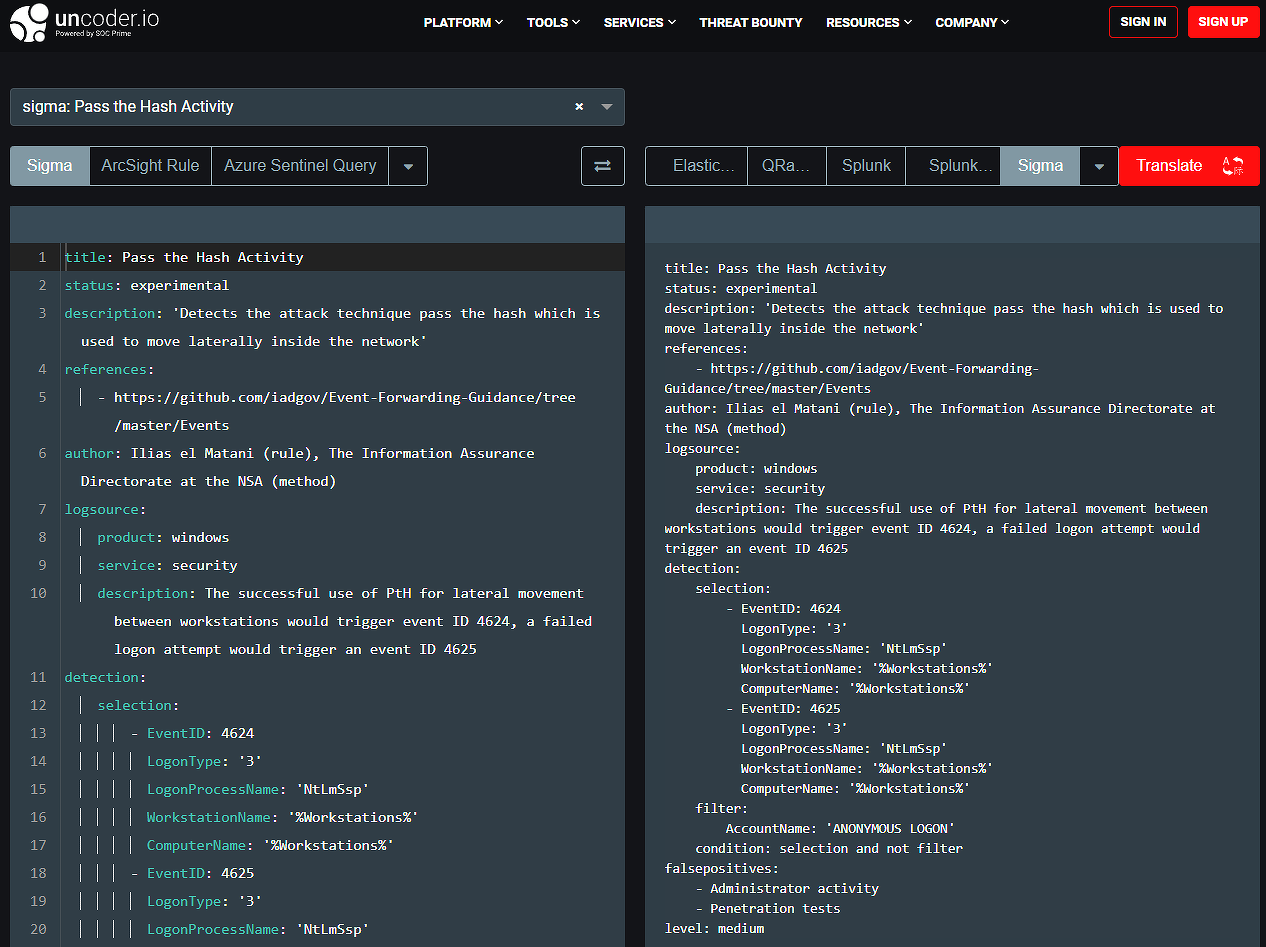
Развивая функционал Sigmac в направлении Detection-as-Code, компания 3CORESec создала проект SIEGMA, использование которого позволяет реализовать автоматические pipeline-внедрения правил детектирования непосредственно в SIEM. К сожалению, на текущий момент поддерживаются только Elastic SIEM и Azure Sentinel.
Те же энтузиасты из компании 3CORESec стали авторами инструмента Automata, который уже максимально приближается к званию управления полным жизненным циклом правил детектирования. Описанный выше SIEGMA-конвертор, получающий Sigma-правила из внешних репозиториев и конвертирующий их в запросы Elastic SIEM, работает в данном проекте в связке с Mitre Caldera, воспроизводящим атомарные действия атакующих. Задачей Automata является обнаружение соответствий внедренных правил и фактических детектирований после прохождения автоматических тестов . Ложноположительные и ложноотрицательные классификации аллертируют в системе для формирования адаптации правил перед внедрением их в промышленную эксплуатацию.
Однако подобную связку не так часто можно увидеть в реальной инфраструктуре. Наиболее часто для тестирования правил корреляции применяется созданная компанией Red Canary библиотека скриптов эмуляции техник атакующего Atomic Red Team. Библиотека содержит более 800 атомарных тестов, структурированных на основании Mitre ATT&CK-техник и снабженных референсами на соответствующие исследования.
Не все компании пока готовы к столь кардинальному шагу как внедрение автоматизированных Adversary Simulation в своих инфраструктурах. Для подобного проекта должна быть создана соответствующая, релевантная продуктиву, тестовая среда, а нужные процессы согласованы со всеми подразделениями. На первоначальных этапах построения жизненного цикла правил детектирования можно обойтись и более простыми инструментами.
Например, приложения Zircolite и Сhainsaw предоставляют возможность протестировать имеющиеся SIGMA-правила непосредственно на evtx-логах, даже без участия SIEM-системы. Это позволяет оценить наличие в инфраструктуре потенциальных источников ложноположительных срабатываний еще до внедрения правила. Немаловажно также отметить, что инструменты отлично работают и с Security Datasets, коллекциями событий информационной безопасности. Zircolite поддерживает поиск не только в evtx, но и в json (формате, который используется в Security Datasets). Это дает возможность проверить собственные или созданные энтузиастами правила на реальных атаках даже без необходимости воспроизведения их вживую.

Последний проект, о котором мы уже упоминали в предыдущей статье, это Atomic-Threat-Coverage. Помимо уже описанных ранее разделов данного проекта, посвященных logging policies и data needed, сотрудники SOC могут найти здесь собственно правила детектирования Detection Rules в Sigma и других форматах. Кроме того, тут размещены референсы, известные условия ложно-положительных срабатываний и скрипты эмуляции атомарных действий атакующего, которые покрываются данным детектированием. В общем смысле это является прообразом карточки инцидента, а точнее тем, что в зарубежной литературе называется Alerting and Detection Strategies (ADS) .
От аналитического отчета до правила детектирования, от необходимой политики логирования до скриптов эмуляции — проекты ATT&CK-сообщества сегодня раскрывают практически полностью тему Detection Engineering. Конечно, они далеки от совершенства и часто больше похожи на Proof-of-Concept, нежели на реально работающие инструменты. Те же Sigma-правила пока что лишены столь важных функций, как join-операторы и агрегации событий. Однако можно с уверенностью сказать, что подобный индустриальный подход к созданию и тестированию правил детектирования событий информационной безопасности переводит Security Operations Center на качественно новый уровень.
В заключение ответим на вопрос многих SOC-специалистов, имеющих сейчас в арсенале лишь несколько десятков правил детектирования и уже сталкивающихся с проблемой ложноположительных срабатываний: «Для чего нужно такое избыточное количество правил, количество которых уже перевалило за тысячу, если существующая команда SOC не справляется и с существующей загрузкой?»
Ответ кроется в статистике и в самой парадигме детектирования: false positive — не тот показатель, который нужно стремиться снижать до нуля. Данный подход проиллюстрировал в своей презентации технический директор SpecterOps Джаред Аткинсон (Jared Atkinson). Ее основная мысль заключается во фразе: «Ложноположительные — это плохо, но ложноотрицательные — хуже». Снижая количество ложноположительных срабатываний, ориентируясь лишь на правила, которые на 100% идентифицируют вредоносную активность (вроде создания неизвестного администратора домена или известные функции mimikatz в командной строке), мы отсекаем огромное количество потенциальных обнаружений широко известных техник атакующего. Мы начали данную статью со ссылки на статью Антона Чувакина, и мистер Джаред Аткинсон также ссылается на мысли этого кибер-евангелиста, однако на статью On Threat Detection Uncertainty. Господин Чувакин, как и многие другие участники кибер-сообщества, занимающиеся темой Detection Engineering, оперирует термином uncertainty (неопределенность). И для детектирования угроз в условиях неопределенности использовать подход строгих и однозначных правил крайне нецелесообразно. Вместо этого он предлагает следующие решения:
Безусловно, выстроить подобную систему без внедрения средств автоматизации и оркестрации практически невозможно. Ни одна компания, даже MSSP, не сможет обрабатывать такие форсированные правила детектирования. Только SOAR-платформы, такие как Security Vison, могут на основании плейбуков обогащений производить автоматический анализ инцидентов, эскалируя на аналитика лишь те из них, которые удовлетворяют установленной критичности полученных данных и являются связанными с уже имеющимися событиями и/или индикаторами в системе. Также лишь SOAR-платформы сегодня позволяют распределять инциденты по линиям SOC в зависимости от загруженности и компетенции сотрудников.
Поделиться
 Короткая ссылка
Короткая ссылка










